 트리 {이진트리, 수식트리, 분리 집합}
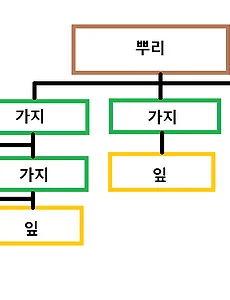
트리: 나무를 닮은 자료구조, 트리는 뿌리(Root), 가지(Branch), 잎(Leaf) 3가지 요소로 이루어져 있음. 뿌리, 가지, 잎은 모두 똑같은 노드이다. 어디에 위치하는가에 따라 불리는 이름이 달라질 뿐. 뿌리 - 트리 자료구조의 가장 위에 있는 노드 , 가지 - 뿌리와 잎 사이에 있는 모든 노드잎 - 가지의 끝에 매달린 노드, 끝에 있다고 해서 단말 노드라고 부르기도 한다. B는 C와D의 부모(Parent), C와 D는 B의 자식(Children), 그리고 한 부모 밑에서 태어난 C와 D를 형제(Sibling)라고 함.B와 K는 아무 관계가 아니다. 경로: 한 노드에서 다른 한 노드까지 이르는 길 사이에 있는 노드들의 순서 I노드에서 K노드 까지 찾아간다면, I, J, K를I에서 K까지의 경..
2025. 4. 17.
트리 {이진트리, 수식트리, 분리 집합}
트리: 나무를 닮은 자료구조, 트리는 뿌리(Root), 가지(Branch), 잎(Leaf) 3가지 요소로 이루어져 있음. 뿌리, 가지, 잎은 모두 똑같은 노드이다. 어디에 위치하는가에 따라 불리는 이름이 달라질 뿐. 뿌리 - 트리 자료구조의 가장 위에 있는 노드 , 가지 - 뿌리와 잎 사이에 있는 모든 노드잎 - 가지의 끝에 매달린 노드, 끝에 있다고 해서 단말 노드라고 부르기도 한다. B는 C와D의 부모(Parent), C와 D는 B의 자식(Children), 그리고 한 부모 밑에서 태어난 C와 D를 형제(Sibling)라고 함.B와 K는 아무 관계가 아니다. 경로: 한 노드에서 다른 한 노드까지 이르는 길 사이에 있는 노드들의 순서 I노드에서 K노드 까지 찾아간다면, I, J, K를I에서 K까지의 경..
2025. 4. 17.




