큐는 입력과 출력 창구가 따로 존재하고 먼저 들어간 데이터가 먼저 나오는 선입 선출(First In-First Out 구조) 자료구조, 큐는 Buffer로 많이 사용함, 큐의 가장 앞 요소를 전단, 가장 마지막 요소를 후단이라고 함.
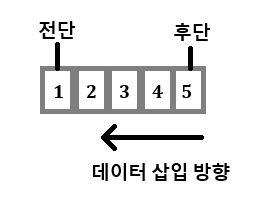
삽입(Enqueue) 연산은 후단, 제거(Dequeue) 연산은 전단에서 각각 수행됨.


큐의 삽입: 후단에 노드를 덧붙여서 새로운 후단을 만드는 연산
큐의 삭제: 전단의 노드를 없애서 전단 뒤에 있는 노드를 새로운 전단으로 만드는 연산
만약 배열을 이용해서 큐를 만든다면?
제거 연산에서 나머지 요소들을 한 칸씩 당기는 비용이 상당하다 -> 전단을 가리키는 변수 도입으로 전단의 위치만 변경.
후단도 후단을 가리키는 변수에 실제 후단 위치 +1을 한 값을 담아 후단이 가리키는 위치에 데이터를 입력하도록 구현.
하지만 이렇게 하면 제거 연산을 수행할때마다 큐의 가용 용량도 줄어듦. 이를 해결하기 위해서 배열 끝과 배열 시작 부분을 이어 효율적인 삽입 / 삭제 연산이 가능하도록 만들어진 큐를 순환 큐(Circular Queue)라고 함.
큐가 포화 상태일때 뿐 아니라 공백 상태일 때 전단과 후단이 만나기 때문에 구분하는 방법이 필요
=> 순환 큐 생성 시 실제 용량보다 1만큼 더 크게 만들어서 전단과 후단 사이를 비운다.
순환 큐는 배열을 기반으로 구현되며 삽입과 삭제 연산이 이루어질 때 전단과 후단을 변경하여 큐가 공백 상태인지 포화 상태인지
확인


순환 큐의 구조체: Capacity는 순환 큐의 용량, Nodes 배열의 크기를 나타내는데 실제로 Nodes를 메모리에 할당할 때는 Capacity+1 만큼의 크기를 할당한다. 노드 하나를 공백/포화 상태 구분 용 더미 노드로 사용하기 때문.
Front는 전단 위치를 Rear는 후단 위치를 가리킨다. 이들은 배열 내 인덱스를 값으로 가진다. Rear는 실제 후단 보다 1 더 큰 값을 가짐.


순환 큐의 생성/ 소멸 연산: 생성 -Node x (Capacity+1)의 크기로 자유 저장소에 할당,
소멸 - 배열을 먼저 자유 저장소에서 제거하고 순환 큐 구조체를 제거함.

노드 삽입 연산: if블록에서 Rear의 값이 *Queue -> Capacity +1과 같은 값이라면 후단이 배열의 끝에 도달했다는 의미이므로 Rear와 Position을 0으로 지정. else인 경우 Rear의 위치를 Position에 저장하고 Rear의 값을 1 증가시킴.
if~else블록을 거치고 나면 Nodes 배열에서 Position이 가리키는 곳에 데이터를 저장합니다.

노드 제거 연산: 전단의 위치(Front)를 Position에 저장. if~ else블록에서 Front 값이 Capacity와 같을 때, 전단이 배열 끝에 도달한 경우 Front를 0으로 초기화하고 그렇지 않은 경우 Front의 값을 1만큼 증가시킴.

공백 상태 확인: 순환 큐의 공백 상태를 확인 전단과 후단의 값이 같으면 공백 상태라는 의미이므로 Front와 Rear를 동등연산자(==)로 비교한 값을 반환한다.

포화 상태 확인: 전단이 후단 앞에 있을 때 후단과 전단의 차 (Rear-Front)가 Queue의 용량(Capacity)과 동일하면 큐는 포화 상태, 또 다른 경우는 전단이 후단과 같은 위치 또는 뒤에 있고 후단에 1을 더한 값(Rear+1)이 전단(Front)과 동일할 때 즉, Rear가 Front 바로 앞 칸이면 포화상태

링크드 큐: 링크드 큐의 각 노드는 이전 노드에 대한 포인터를 이용해 연결되므로 삽입 연산을 할 때는 삽입하려는 노드에 후단을 연결하고 제거 연산을 할때는 전단 바로 다음 노드에서 전단에 대한 포인터를 거두기만 하면 됨.
용량 제한이 없어 가득 찬 상태인지 확인할 필요가 없다.
순환 큐와 링크드 큐의 차이점: 성능은 순환 큐가 더 빠르다. 필요한 큐의 크기를 미리 정할 수 있고 고성능이 요구되는 상황에선 순환 큐가 더 좋다. 구현은 링크드 큐가 더 쉽다.

링크드 큐 노드 구조체: Data필드의 자료형이 ElementType이 아니라 Data Type이라는 점만 제외하면 링크드 리스트 노드 구조체와 동일하다.
여기서 ElementType은 큐나 리스트가 다루는 일반적인 데이터 자료형을 typedef로 만든 별명이고
DataType은 복합데이터 구조를 나타내는 사용자 정의 구조체다.

링크드 큐 구조체: 큐의 전단을 가리키는 Front, 두 번째는 큐의 후단을 가리키는 Rear, 마지막은 노드 개수를 나타내는 Count
큐는 전단과 후단에서 각각 삭제와 삽입 연산을 하기에 필요.

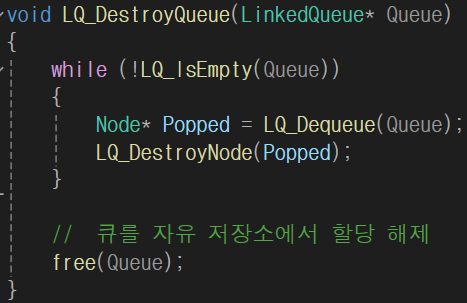
링크드 큐 생성/소멸 연산: 생성 - LinkedQueue 구조체를 자유 저장소에 생성하고 구조체의 각 필드를 초기화.
소멸- 큐 내부에 있는 모든 노드를 자유 저장소에서 제거하고 마지막에는 큐도 자유 저장소에서 제거

노드 삽입 연산: 후단에 새로운 노드를 붙이는 것만으로 간단히 구현
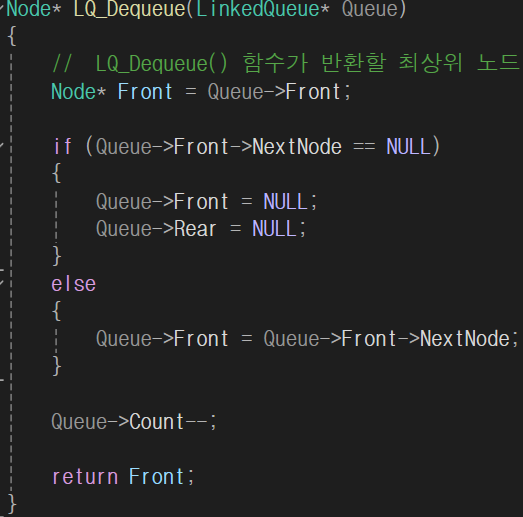
노드 제거 연산: 전단 뒤에 있는 노드를 새로운 전단으로 만들고 전단이었던 노드의 포인터를 호출자에게 반환.
'자료구조' 카테고리의 다른 글
| 정렬 알고리즘 {버블 정렬, 삽입 정렬, 퀵 정렬} (0) | 2025.04.17 |
|---|---|
| 트리 {이진트리, 수식트리, 분리 집합} (0) | 2025.04.17 |
| 스택 {배열 기반 스택, 링크드 리스트 기반 스택} (0) | 2025.04.15 |
| 리스트 {링크드 리스트, 더블 링크드 리스트, 환형 링크드 리스트} (0) | 2025.04.15 |
| 자료구조란 (0) | 2025.04.15 |



