스택 {배열 기반 스택, 링크드 리스트 기반 스택}
스택은 데이터를 바닥에서부터 쌓아 올리는 구조. 스택에서의 입 / 출력은 오직 스택의 꼭대기에서만 이루어짐. 스택 맨 아래에 있는 데이터를 꺼내려면 그 위의 데이터를 모두 걷어내야 한다. Last In-First Out , First In- LastOut


스택의 주요 기능은 삽입(Push)과 제거(Pop) 나머지 연산은 두 연산을 위한 보조 연산.
삽입 연산: 스택 위에 새로운 노드 (요소)를 쌓는 일.
제거 연산: 스택에서 최상위 노드를 걷어내는 것.
배열 기반의 스택: 스택 생성 초기에 사용자가 부여한 용량만큼의 노드를 한꺼번에 생성. 최상위 노드의 위치를 가리키는 변수를 두고 삽입과 제거 연산을 수행.

배열 기반 스택의 노드 구조체: 데이터만 담는 구조체로 표현됨.

배열 기반의 스택 구조체: 용량과 최상위 노드의 위치, 노드 배열 3가지 필드를 가지고 있어야 함.
용량: 스택이 얼마만큼의 노드를 가질 수 있는지 알기 위해 사용.
최상위 노드 위치: 삽입/제거 연산 시 최상위 노드에 접근할 수 있게 하려고 사용.
노드 배열: 스택에 쌓이는 노드를 보관하는 데 사용.
Nodes 포인터에는 자유 저장소에 할당된 배열의 첫 번째 요소를 가리킨다.

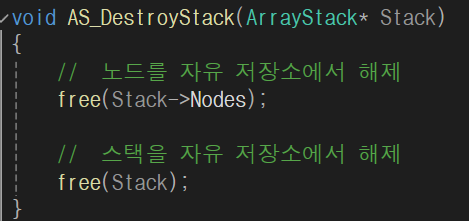
스택 및 노드 생성/소멸 연산: 매개 변수 2개인데 첫 번째는 ArrayStack의 구조체이고 두 번째는 스택의 용량을 나타내는 노드 개수.
malloc() 함수가 2번 호출, 처음 호출된 malloc() 함수는 ArrayStack을 자유 저장소에 쌓기 위해 사용, 두 번째는 매개변수로 입력된 개수만큼 노드를 미리 생성하는 데 사용됨. Top을 0이 아닌 -1로 초기화하는 이유는 C언어에서 첫 번째 배열 요소를 가리키는 첨자가 0이므로 비어 있는 스택의 최상위 위치가 이보다 작아야 하기 때문. Top는 노드가 삽입될 때 1씩 증가, 노드가 삭제될 때 1씩 감소. 사용이 끝난 자유 저장소는 반드시 정리해줘야 함. free() 함수도 2번 사용해서 노드와 스택을 각각 해제함.

삽입 (Push) 연산: 최상위 노드의 인덱스 (Top)에서 1을 더한 곳에 새 노드를 입력하도록 구현.

제거(Pop) 연산: Top값을 1만큼 낮추도록 구현, 최상위 노드에 있던 데이터를 호출자에게 반환해야 함.


이처럼 다른 연산자들도 있지만 보조 연산이다.
링크드 리스트 기반 스택: 스택 용량에 제한을 두지 않아도 된다.

링크드 리스트 기반 스택의 노드 구조체: 배열 기반 스택 노드와 달리 자신의 위치 위에 위치하는 노드에 대한 포인터를 가지고 있어야 한다. Data 필드가 char형 포인터로 선언된 이유는 배열 기반과 달리 링크드 리스트 기반 구조는 동적으로 크기가 바뀌어야 하고 문자열을 자동메모리에 저장할 경우 함수가 끝나면 메모리에서 자동으로 삭제되는 문제가 발생한다. 그래서 문자열을 자유 저장소에 저장시키고 이를 포인터로 보관하는 구조. char* Data는 자유 저장소에 할당된 문자열의 주소를 가리키고 NextNode 포인터는 자기 위에 쌓여있는 노드의 주소를 가리킨다.

링크드 리스트 기반 스택의 구조체: 링크드 리스트의 헤드와 테일에 대한 포인터가 필요, List 포인터는 데이터를 담는 링크드 리스트를 가리키고 Top 포인 터는이 링크드 리스트의 테일을 가리킴. 스택에서는 나중에 들어온 데이터가 가장 먼저 나가는 구조이기 때문에 가장 최근에 들어온 데이터인 테일의 위치가 스택에서는 최상단 위치이다.


스택 생성/소멸 연산: 스택을 malloc() 함수로 자유 저장소에 할당, 소멸 연산에서는 먼저 각 노드를 제거하고 구조체를 할당 해제함.
LLS_IsEmpty() 함수로 스택이 비어 있는지 점검하고 LLS_Pop() 함수는 스택의 최상위 노드를 제거, LLS_DestroyNode() 함수는 자유 저장소에 할당된 노드를 메모리에서 해제함.

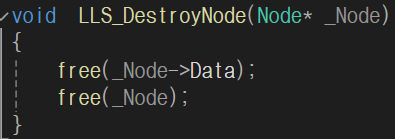
노드 생성/소멸 연산: malloc() 함수가 2번 호출되는데 Node 구조체 할당에 한 번, Node구조체의 Data 필드 할당에 한 번 호출, free() 함수도 따라서 2번 호출된다.

노드 삽입 연산: 스택의 최상위 노드 Top에 새 노드를 얹도록 구현. 새 노드가 최상위 노드가 된다.

노드 제거 연산: 1단계 - 현재 최상위 노드(Top)의 주소를 다른 포인터로 복사
2단계 - 새로운 최상위 노드의 바로 아래 이전 노드를 찾는다.
3단계 - LinkedListStack 구조체의 Top 필드에 새로운 최상위 노드의 주소를 등록한다.
4단계 - 1단계에서 저장했던 예전 최상위 노드의 주소를 반환한다.



그 외의 간단한 연산들
스택을 응용한 계산
중위 표기법 : 1 +3과 같이 평소 사용하는 표기방법
후위 표기법 : 1 2 + 과 같이 연산자가 피연산자 뒤에 위치한다는 규칙을 가짐
후위 표기식 계산 알고리즘
1번째 규칙 : 식의 왼쪽부터 요소를 읽어내면서 그 요소가 피연산자라면 스택에 삽입할 것.
2번째 규칙: 연산자가 나타나면 스택에서 피연산자 2개를 꺼내 연산을 실행하고 그 연산 결과를 다시 스택에 삽입할 것.
이런 식으로 식을 모두 읽으면 스택에는 식의 최종 계산 결과만이 남는다.
이때 스택에 피연산자가 1개인데 연산자가 등장하면 스택 언더플로우가 발생함.
스택 언더플로우(Stack Underflow)는 스택을 꺼내려(pop) 하는데, 꺼낼 값이 없는 경우에 발생하는 오류 상황.
토큰: 텍스트 분석에서 토큰이란 최소단위의 기호 또는 단어를 의미.
중위 표기식을 후위 표기식으로 바꾸는 알고리즘 (데이스 크라 알고리즘)
중위 표기법에는 후위 표기법에 없는 '(' , ')'가 있다. 우선순위가 바뀌기 때문에 중위 표기식을 후위 표기식으로 바꿀 때는 이 괄호의 처리가 아주 중요하다.
1-입력받은 중위 표기식에서 토큰을 읽는다.
2-토큰이 피연산자라면 토큰을 결과에 출력함.
3-토큰이 연산자(괄호 포함)라면 스택 최상위 노드에 담긴 연산자가 토큰보다 우선순위가 높은지 검사(검사가 끝나면 최상위 노드보다 우선순위가 높은 연산자는 남아있지 않게 됨) 검사 결과가 참이면 최상위 노드를 스택에서 꺼내 결과를 출력, 검사 작업을 반복해서 수행하되 그 결과가 거짓이거나 스택이 비면 작업 중단.
4-토큰이 오른쪽 괄호 ')'면 최상위 노드 왼쪽 괄호 '('가 올 때까지 스택에 제거 연산을 수행하고 제거한 노드에 담긴 연산자를 출력. 왼쪽 괄호를 만나면 제거만 하고 출력하지 않음
5. 중위 표기식에 더 읽을 것이 없다면 반복을 종료하고 더 읽을 것이 있다면 1단계부터 다시 반복한다.